

January 15, 2019
When you hear the phrase, algorithms for machine learning, it can seem like it is something from Star Trek. It may seem futuristic, confusing and beyond what a normal person can understand. This could not be further from the truth.
With machine learning, it is all about the algorithms you use. Each algorithm is going to tackle a problem differently and there is no one algorithm for machine learning. You will need different algorithms for each situation. Therefore, it is a good idea to try out different types of algorithms to see which is going to work best. You evaluate how each one works and then you pick the one that gives you the most efficiency and best result.
List of the Contents:
- General idea
- Support vector machines
- Linear regression
- Logistic regression
- Linear discriminant analysis
- Classification and regression trees
- K-nearest neighbors
- Learning vector quantization
- Boosing and AdaBoost
- Bagging and random forest
- Naive Bayes
- In conclusion
Think of it this way. When you are working on your car, you are going to use a wrench, screwdriver and more. Those tools are your algorithms in machine learning. You don’t go to work on the car with a helium tank, broom, and bullhorn. Those are tools that don’t work for that job.
THE UNDERLYING IDEA
All algorithms for machine learning essentially learn a target function. This target function is what best maps the variables for input to a variable for output. If we label the target function as L and the input and output variables as f and w, then we get a formula of W = L(f).
In that algorithm, we are making a prediction on what is going to happen in the future. This is what W is. We are basing that prediction on the input variable of f. There is no way to know what the L, or function is yet.
In machine learning, the W=L(f) algorithm is called predictive modeling.
With predictive modeling like this, we want to minimize the error that we receive. This essentially translates into making the most accurate type of prediction that we can.
Let’s dive into the 10 machine learning algorithms that are used by professional data scientists for building machine learning applications.
SUPPORT VECTOR MACHINES
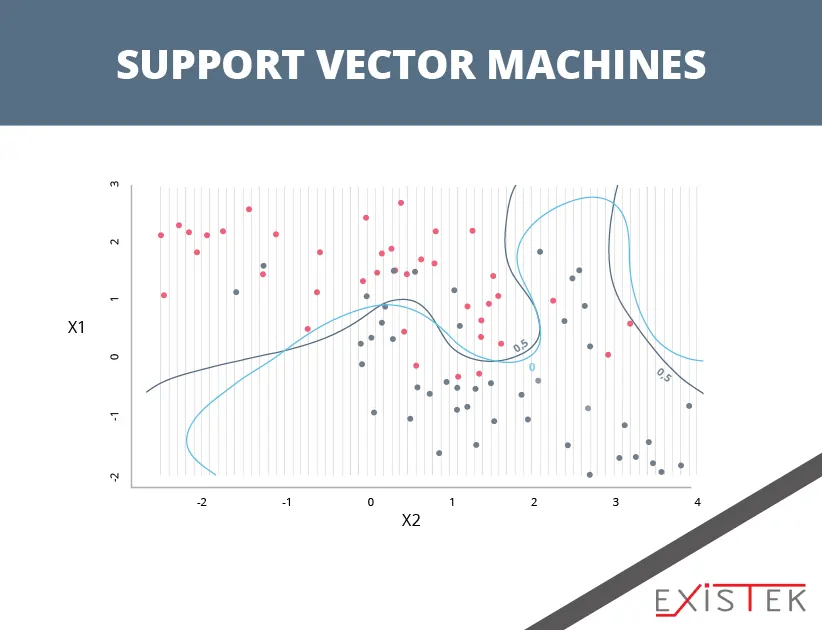
This is one of the most popular algorithms for machine learning and it is also one of the most talked about. The algorithm uses a hyperplane, which is a line that splits in the input variable space. In this algorithm, a hyperplane is going to be selected that best separates the points in the space. It does this by their class, which is either 0 or 1. If you are working in two dimensions, then you can visualize the hyperplane line and assume the input points can be separated by that line. The algorithm will then find the coefficients that provide the best results for separation of the classes by the line.
The distance between the best data points and the hyperplane is called the margin. The best hyperplane that can provide separation of the two classes is the one that has the largest margin. When defining the hyperplane, only these points are going to be relevant. These points are then called the support vectors. They are called this because they essentially support, or also known as define, the hyperplane. This algorithm for machine learning is most often used to find the various values for the numerous coefficients that will maximize the margin.
Support Vector Machines algorithm for machine learning is one of the best and most powerful classifiers and it is worth trying to use in your dataset.
LINEAR REGRESSION
It is the most well-known of the algorithms used in machine learning, especially when it comes to statistics, and linear regression is one of the most well-understood as well. It has been around for two centuries and, as a result, has been studied heavily.
When we work with predictive modeling, we will take algorithms from other fields. These fields can be statistics, like with linear regression, and can be used towards machine learning.
Linear regression is represented in a machine learning algorithm where a line shows a relationship between the input and output variables. This is done by finding the weightings for the input variables, which are called coefficients. If the x and y are the input and output, then B would be the coefficients.
This then creates the algorithm of y = B0 + B1 *x.
We can then predict what y is going to be based on x. With linear regression, the goal is always to find what the values of B0 and B1 are going to be. Different techniques can also be used to determine the model of linear regression from the data provided, including using linear algebra.
This is an excellent type of algorithm because it is quick, easy and if you are new to algorithm machine learning, the best algorithm to try first.

LOGISTIC REGRESSION
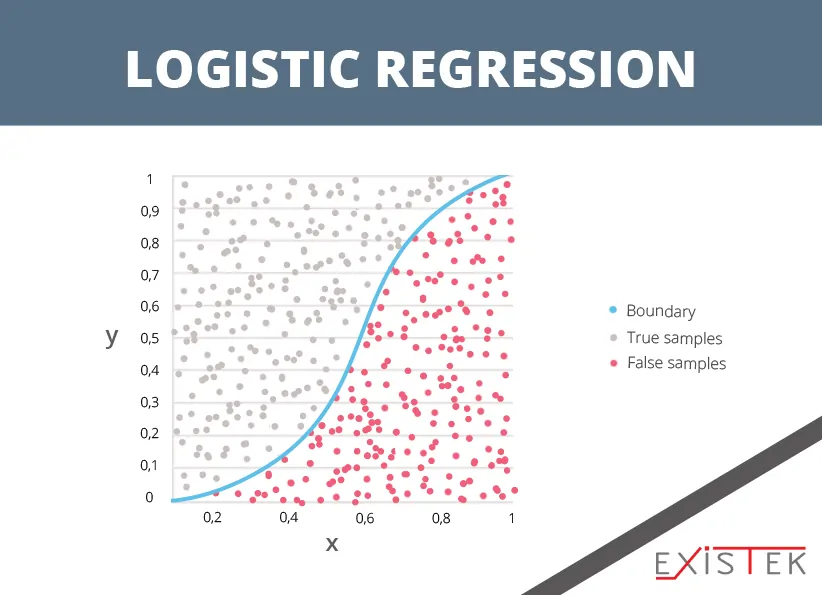
Also coming from the field of statistics is logistic regression. For binary classification problems or problems that have two different class values, this is the algorithm used. Much like linear regression, logistic regression finds the values that provide weight to each of the input variables. Rather than using a linear function like in linear regression, the output prediction comes from a logistic function. This function is non-linear.
Transforming any value to a 0 or 1, this algorithm is helpful because all undefined values can be made to 0 or 1. The algorithm is very useful when it comes to giving more of a rationale towards any prediction. This is because predictions can be made through the logistic regression that gives the probability of any data instance that belongs to either a class 1 or 0.
Much in the same way with linear regression, logistic regression works the best when attributes are removed that do not relate to the output variable. You can also remove any attributes that are like each other. A big benefit to this type of algorithm for machine learning is that it is a very fast algorithm to learn and excellent for classifying problems that are binary.
LINEAR DISCRIMINANT ANALYSIS
When you have a classification problem that is two class, then you are going to use linear regression. If you have a problem that uses more than two classes, then the linear discriminant analysis is the algorithm you want to use. Thankfully, the representation of this algorithm for machine learning is very easy and it will consist of the properties in your data that are statistics and will calculate each class. This means that for one input variable, you will have the class mean value for each class and for all classes you will have the variance calculation.
Through this algorithm for machine learning, predictions are made by looking at each class and calculating the discriminate value, hence the name. It also makes a prediction for the class that will have the value that is the largest. This algorithm assumes that you are using data with a bell curve, so you will want to make sure you don’t have any outliers before using this algorithm. This algorithm is simple and very powerful as a method for dealing with problems that involve predictive modeling classification.

CLASSIFICATION AND REGRESSION TREES
When you are doing predictive modeling in machine learning, decision trees are used extensively as an algorithm. The decision tree is essentially a binary tree and involves algorithms and data structures. Each node of the tree will represent x, which is your input value, and a split point of the variable. This assumes that the variable is numeric.
The prediction is created through y, the output variable and predictions are made by going through the splits on the tree until there is a leaf node that you arrive at. The output of the class value will be at that leaf node.
Regression and classification trees are very fast to learn and very fast when it comes to making predictions. Another big benefit is that they are very accurate through a wide range of various problems and you do not have to prepare your data in any specific way.

K-NEAREST NEIGHBORS
Also known as KNN, this algorithm for machine learning is extremely effective and easy to use. With this algorithm, you are making predictions for new data by going through the training set for the most instances of K, or the neighbors. Then you are summarizing an output variable for all those K instances. If you are dealing with regression problems, then the K instances will be a mean output variable. If you are dealing with classification problems, then you are getting the most common class variable.
What you need to do when using the KNN algorithm for machine learning is determine how similar the data instances are to each other. The best way to do this, if all your attributes are working on the same scale, kilometers, for example, is to use Euclidean distance. This number can then be calculated directly depending on the differences for each of the input variables.
One of the drawbacks of this algorithm for machine learning is the fact that it uses a lot of memory and it uses a lot of space to store everything. This is because it uses the just-in-time method of calculation, where it only performs any sort of calculation if a prediction is needed at that moment.
The curse of dimensionality is a problem for this algorithm because the distance or closeness can break down when you have many input variables. Therefore, you should only use input variables that are the most relevant to predicting the output variable.

LEARNING VECTOR QUANTIZATION
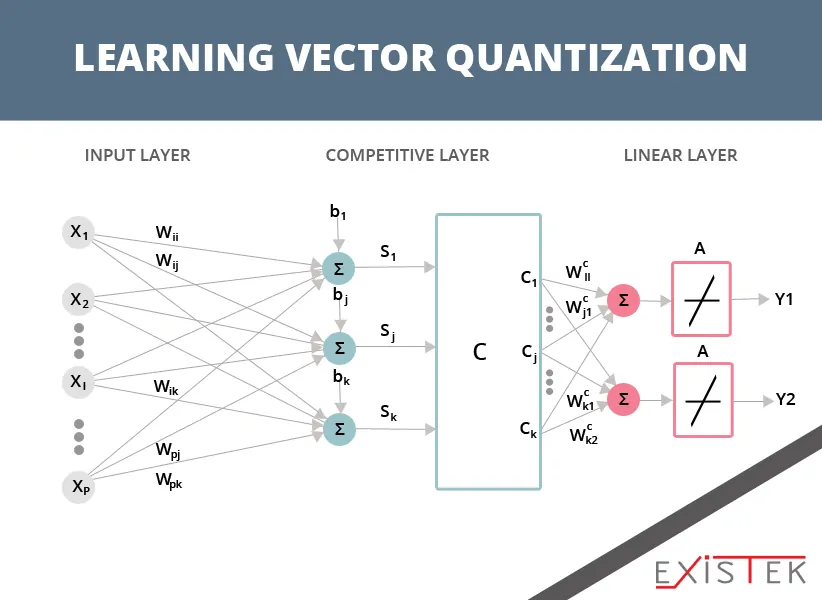
When you are dealing with KNN, you are using your entire training dataset. That is using a lot of memory. This is where the learning vector quantization algorithm for machine learning comes in. Also called LVQ, it is an algorithm that is an artificial neural network. This allows you to make the choice about how many different training instances you are going to have running. It then learns exactly what each of those instances should look like. In order to represent LVQ, there is a codebook vector collection. These are each selected on a random basis at the start of the algorithm and then it is adapted to summarize the dataset in the best way, over several iterations of the algorithm.
Once learned, it will work the same way as the KNN algorithm using codebook vectors to find the neighbor that is the most similar. This is done by calculating the total distance between each of the vectors and the new instance of data. The class or real value if it is a regression, for the matching unit is then outputted as the prediction. In order to achieve the best results with this equation, you should rescale your data so that it has the same range. This works best with 0 to 1.
If you like KNN and it works well for you, but you don’t like that it has a huge memory draw, then LVQ is an excellent option for you.
BOOSTING AND ADABOOST
This ensemble algorithm for machine learning creates a classifier that is strong from a series of weak classifiers. The way that it does this is by building you a model using the training data. It then creates a second model to correct errors that may be present in the first model. At this point, models are added until the set is predicted in a perfect manner, or the maximum number of models are added.
AdaBoost is the first successful algorithm that uses the boosting method, developed for the use in the classification of binary values. If you want to understand boosting, it is a great way to begin. Modern boosting algorithms build on this base algorithm. AdaBoost will use a short decision tree. After the first tree has been developed, the performance of each of the trees on each instance is then weighted to how much attention it will give to the next tree. If training data is difficult to predict, then it will be given more weight compared to data that is easier to predict.
Models are created one after the other in this algorithm for machine learning and once all the trees have been created, predictions will then be made for each of the data that is new. The performance of the tree, each of them, is then weighted to see just how accurate it is on the training data.

BAGGING AND RANDOM FOREST
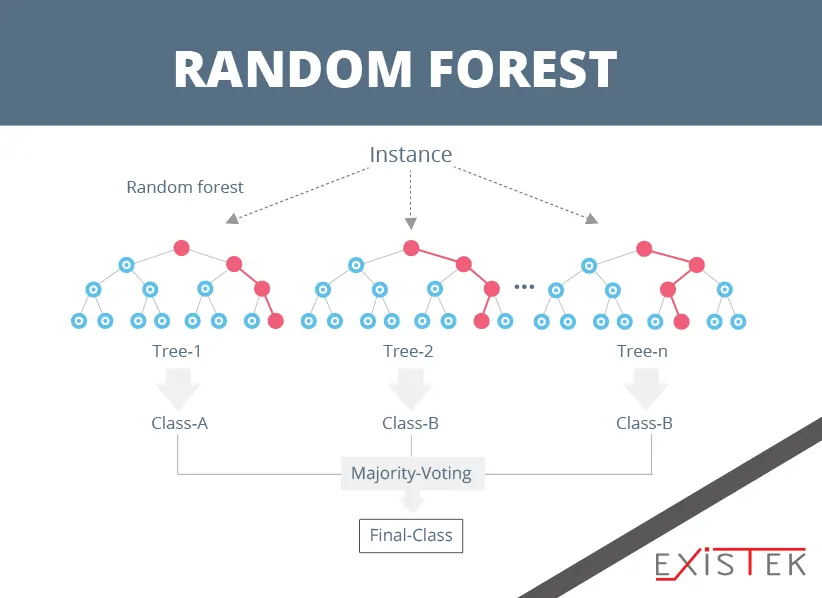
An odd name yes, but Random Forest is arguably one of the most powerful of the algorithms for machine learning. It is also one of the most popular ones as well. Where does the bagging name come from? It comes from the fact that this machine learning algorithm uses bootstrap aggregation, also known as brag.
If you want to measure or estimate a quantity from a data sample, then bootstrap is going to be the most powerful method to do this. Using the bootstrap algorithm for machine learning takes a lot of samples from the data, then it calculates your mean and provides you with an average for the mean values. This gives you an excellent estimation of what the true mean is going to be. Bagging will use this same approach, but it will give you an estimation for the entire model of statistical data. Usually, this will be done in the form of the decision tree. For each data sample, multiple samples of the training data are then generated. If you need a prediction for the new data, each of these models is going to offer a prediction and each prediction will be averaged to give you a better estimation of the output value.
What about random forest then? Well, that is an adjustment to this approach. It creates decision trees but rather than selecting the optimal points to split, it uses suboptimal split points to introduce some extra bit of randomness. Models are then created for each data sample, making them more different than before but also accurate. If you combine all the prediction results, you get a better estimation of the underlying value of the output variable. If you are getting excellent results with decision trees, then you will get better results with this algorithm for machine learning.
NAIVE BAYES
It may have an odd name but when it comes to algorithms for machine learning, it is extremely powerful and very simple.
With the Naïve Bayes algorithm, you are taking two different types of probabilities and calculating them using your training data. You will get a probability for each of the classes you have, and you will get a conditional probability with an x value for each class. When you calculate using this algorithm, the probability model can be used to obtain the prediction with new data using the Bayes Theorem. If you have real-valued data, it is common to use the bell curve.
So, what about that name? Well, since it uses the Bayes Theorem, that is part of it, but the naïve part is because it assumes that each of the input variables are going to be independent. For complex problems, this is a very effective algorithm for machine learning.
IN CONCLUSION
There is no such notion as the best and the worst algorithms for machine learning. The simple truth is that each algorithm will perform differently depending on the tasks you need your machine learning application to perform and what data set it has to consume. Even the best data scientists won’t be able to tell you what approach will suit your purposes most without trying various algorithms first. In this article, we have mentioned only a few most simple algorithms for machine learning, yet still, it will be a good start for the beginners.
If you’re thinking about leveraging the power of machine learning for your business or using it in your application – we can help you. Existek is a custom software development company with extensive experience in the AI field. Contact us via the form at our contact page or start the dialogue in the chat widget to the right and we’ll be able to discuss your project right away.